Blog Post series
- How to optimize .net development using .net core 2.1 and C# 7.2, introduction to fundamental concepts. (this post)
- Introduction of working with
struct.
Forewords
This is the first blog post of a series about understanding how to improve performances developing with .net core and C# 7.2.
Some parts are purely theory, so it’s not about .net or C# 7.2, but it’s mostly the first post of the series, for the reader to understand the basics of CPU and Memory.
This series is intended for any kind of readers, especially the ones who a not familiar with the topic and are willing to understand the basics.
For the experts on the matter, you may find these posts are lacking depth, but it’s on purpose: the goal is not to thoroughly explain everything, it would be too big and ending up confusing most readers, but instead explaining what matters, why it matters and how to deal with it.
- Understanding the memory.
- The benefits of working with
struct. - Working with Data Stores.
- Working with
Memory<T>andSpan<T>.
If you have remarks, typo corrections, or simply read posts still in progress, you can check my dedicated GitHub repo.
Introduction
It’s not a secret that Microsoft decided to focus on improving performances for the 2.1 release of .net core.
The main driver is to improve asp.net core but it doesn’t mean the new features only target the web server. Most of the time when it’s about performances you have to dig to the lowest layer in order to bring game changers and this time was no exception.
What is interesting, from my point of view, is that we’re starting to see some features that bring us closer to low level/high performance language such as C++.
The goal of this post series is to :
- Explain what matters when we’re dealing with optimization.
- How you can use the new features (and also some of the old ones) to improve the code speed while keeping things clean and well designed.
C# is about writing clean code to achieve high maintainability and meet good programming practices/standards. Writing optimized code often drives you away from these principles, finding the right balance is definitely a key aspect for the programmer.
Why .net is slower than C++ ?
Well, there are many reasons and I won’t detail all of them, mostly because I couldn’t, but there’s some of them we can focus on:
- Seamless control over the lifetime of object through the use of Garbage Collection. It scares people who are performance/real-time driven.
- No direct access to memory, through pointers and boundless checks (we are not considering unsafe .net, of course).
- It is easy to not pay attention to the layout of the data.
- A lot of implicit memory copy. Things are easy to develop, but under the hood you don’t realize all the memory bandwidth that is consumed.
- A JIT that doesn’t generate code as efficient as a pre-compiled language.
C# is a pretty high level programming language, it’s pretty easy/safe to use, that’s why you have things like the bullets #1 to #4 above. On the other hand it’s also easy to not being aware of what matters to optimize things up.
Let’s not focus on the #5, because there’s few things we can do about it. If we take a close look at #1 to #4 we will see there’s a common theme: memory!
Is memory important? Yes, you bet!
A bit of talk about memory
CPUs are getting more and more powerful the years passing by, but we don’t see the same trend going on for memory, see below:
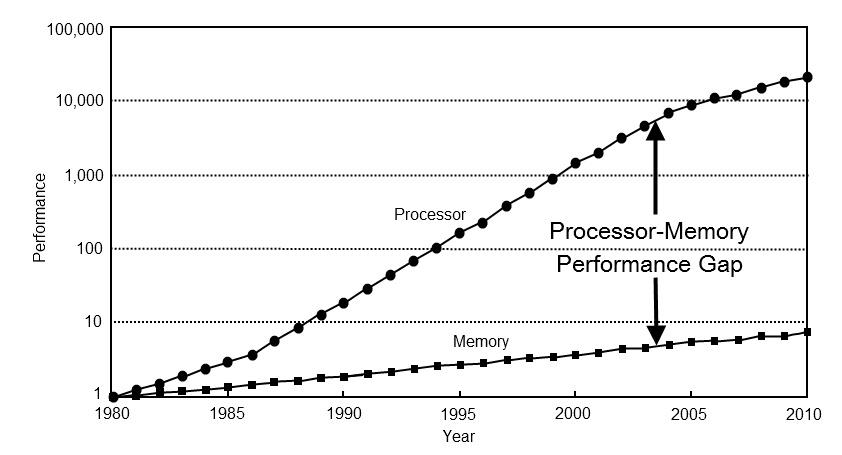
Computer Architecture: A Quantitative Approach by John L. Hennessy, David A. Patterson, Andrea C. Arpaci-Dusseau
It means that in order to keep the CPU busy, we have to develop our code & data in a memory friendly way, because accessing data directly to memory will cost more than you may think!
There’s a very good analogy that you can read here that basically gives you crucial information.
Let’s summarize it.
Today, most of the CPU instructions that don’t involve memory access or very complex computation will take one cycle to execute, you have a 4Ghz CPU so it’s 4 billions instructions per second per logical core (so 32 billions for a hyper-threaded quad cores).
Let’s scale things to understand their impact better:
| Access type | Real duration | Scaled duration |
|---|---|---|
| One CPU Cycle | 0.4ns | 1 second |
| Cache L1 Access | 0.9ns | 2 seconds |
| Cache L2 Access | 2.8ns | 7 seconds |
| Cache L3 Access | 28ns | 1 minute |
| Main memory Access | ~100ns | 4 minutes |
Compared to one CPU cycle:
- L1 access is 2x slower
- L2 access is 7x
- L3 access is 60x
- Memory access is 250x slower!
So yes, you can understand that the more you are memory friendly (we’ll explain roughly what it implies) the better you’ll have chances to hit the CPU cache, getting you significant performance boost!
Put it differently, compared to main memory access:
- A L1 access is 125 times faster.
- A L2 access is 38 times faster.
- A L3 is 3.5 times faster.
So worrying about the JIT not being fast enough may not be the main reason, you can leverage things yourself by being aware of what the CPU needs to execute as fast as possible.
Being memory friendly, means being cache friendly!
There are a lot of good, in-depth articles/posts out there explaining why the CPU cache is important and how to work with it. This topic can get really complex very quickly, here, again, we will try to keep things simple.
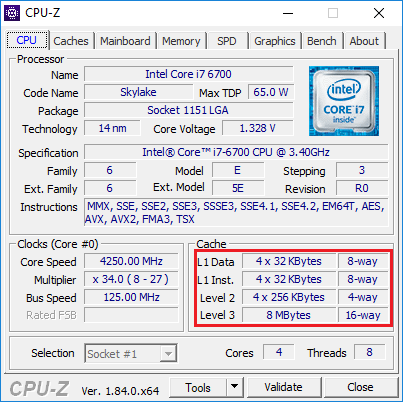
Few explanations/remarks:
- Level 1 cache has dedicated cache for Data and Instructions (running assembly code), this is important because we don’t want one to compete against the other.
4 x 32KBytes, here the ‘4 x’ means we’ve a dedicated cache for each Core of the CPU: that’s right L1/L2 have dedicated caches for each CPU Core. ’32KBytes’ is the size of each for one CPU Core.8-wayis about ‘associativity’, which is a rather complex topic. Follow the link is you’re curious and brave!- Data in a CPU Cache are organized by ‘Line’ (or Block), which are now most of the time 64 bytes wide. It means that whatever you do, when a data is loaded in the cache, it will fill a whole Line of 64 bytes and the starting address will also be a multiple of 64 bytes (hence the importance of allocating memory with a starting address being a multiple of 64 bytes).
- The CPU likes to prefetch data. Prefetch means that it will read ahead data that follows the one you’re accessing, hoping that you will access your data sequentially. Which is why it is a good thing to pack the data you often access at the same time in the same memory zone.
More about how a CPU cache works.
Enough of the theory, how could we make things faster in .net?
Minimizing the usage of the Garbage Collection
Yes, the GC is a very nice and handy feature, but as each feature, it’s not a silver bullet, it’s not something you have to rely on 100% of the time, and definitely not in .net! The GC is only used when you involve class based types, struct ones are not. So yes, there’re ways to minimize pressure on the GC and you should know about them!
Direct/fast memory access, avoiding copies
It’s easy to copy data, to isolate it for the sake of a good design (or easy and well readable code), it may not harm when the size is small and the frequency of the operation is low, but when one of these two factor increase, things amplify and performances are dropping.
One of the best example is the String class, it’s allocated on the heap and it’s immutable, which means all methods that change the string will return a new object! It’s a lot of memory traffic and the developer is most of the time not aware of this.
Luckily for us we have new weapons to improve things on this area.
Designing the data in a more memory friendly way
C# is a high-level language, we don’t pay attention to how we define the data in the types we design and it’s a big mistake when we want things to be driven by performances. Again, this is more about convenience, because the language don’t prevent you to improve things: you just don’t know/care to do it.
To be followed !
This was just the first post of the series and we talked mostly about theory, it was important to lay these foundations for the posts to come.
Starting the next post we’ll start talking concrete stuffs with examples.
Profiles

Languages
 Francais
FrancaisBlogroll
![]()